


どーも!
たかぽんです!
今回はLaravelでN+1問題という設計上発生してしまう問題についてしっかり理解していこうと思います!
実際はLaravelに限らず、より一般的なWeb開発等で発生しがちな問題なんですが、特にLaravelの場合どのように発生するのか?
そして、どうやって解消すればいいのか?を調べていこうと思います!
目次
N+1問題とは・・・?
さて、ではこのN+1問題を理解していこうと思います!
WEBで様々なサービスを設計する際、DBから値の取得を行うシーンはたくさんありますよね。
全てのユーザーに紐付いているコメントリストに対して処理をする...
全てのイベントに紐づいている顧客リストに対して処理をする...
などなど...
そういった状況で、SQLのクエリを発行して情報を集めていく必要がありますが、その際、余分にたくさんのクエリを発行してしまい、少なからず表示速度等に悪影響を出してしまうことをN+1問題と言います。
イメージとしては、ユーザーがたくさんのコメントをできるサービスがあったとします。
その際、一度Userモデルで特定Userの情報を取得し、その後、そのユーザーのコメントを取得するためにたくさんのクエリを走らせてしまいます。
実際には一度目のUserモデルから取得する際に合わせてCommentモデルの値を持ってくる...と言った形にすれば発行されるクエリは一件で済むわけですね。
今回は実際に簡単な環境下で試してみて行ってみます。
前半はあまり関係ない環境作りなので、結果だけ気になる方は
"N+1を発生させる"の節からご覧ください。
今回は適当なユーザー情報を保存するテーブル(Users)と、そのユーザーが発言したコメントを保存するテーブル(Comments)で考えてみようと思うので、それを作っていきます!
検証用のテーブルを作成
では、まずは検証用のテーブルをDBに作っていきます。
laravelのmigrationで行うので、migrationがよくわからない方は以下の記事を読んでみてください。
migrationでは以下のようにupを指定して新規でテーブルの作成をします。
まずはtest用userのテーブル。
...
...
...
public function up()
{
Schema::create('testusers', function (Blueprint $table) {
$table->id();
$table->timestamps();
$table->string('name'); // ユーザー名
$table->string('old'); // 年齢
});
}
...
...
...
そしてコメント用のテーブルです。
...
...
...
public function up()
{
Schema::create('comments', function (Blueprint $table) {
$table->id();
$table->timestamps();
$table->foreignId('user_id');
$table->string('comment');
});
}
...
...
...
上記のファイルを作成したら、"php artisan migrate"で作成できます。
完成したら、次です!
最低限のデータを入れる
では、検証用にテストデータを入れましょう!
今回はSeederを使用して入れました。
Seederについてはまた別の記事で解説できれしようと思いますが、今回は割愛します。
Seederを使わず、Userを一人追加してそれに対するコメントを数件登録する...程度でも大丈夫です。
ちなみに入っているデータは以下のような形です。
takapon-test=> select * from test_users;
id | created_at | updated_at | name | old
----+---------------------+---------------------+-------------------------+-----
1 | 2020-10-24 16:56:39 | 2020-10-24 16:56:39 | Rocky Thiel | 95
2 | 2020-10-24 16:56:39 | 2020-10-24 16:56:39 | Gay Ziemann Sr. | 74
3 | 2020-10-24 16:56:39 | 2020-10-24 16:56:39 | Dr. Lysanne Herman MD | 45
4 | 2020-10-24 16:56:39 | 2020-10-24 16:56:39 | Kenneth Friesen I | 7
5 | 2020-10-24 16:56:39 | 2020-10-24 16:56:39 | Ms. Angelita Friesen | 81
6 | 2020-10-24 16:56:39 | 2020-10-24 16:56:39 | Mr. Vinnie Bogisich DVM | 86
7 | 2020-10-24 16:56:39 | 2020-10-24 16:56:39 | Prof. Flo Monahan | 77
8 | 2020-10-24 16:56:39 | 2020-10-24 16:56:39 | Pearlie Kiehn | 78
9 | 2020-10-24 16:56:39 | 2020-10-24 16:56:39 | Mr. Lourdes Lowe IV | 10
10 | 2020-10-24 16:56:39 | 2020-10-24 16:56:39 | Kristoffer Dickinson | 5
(10 rows)
takapon-test=> select * from comments;
id | created_at | updated_at | test_user_id | comment
----+---------------------+---------------------+--------------+--------------------------
1 | 2020-10-24 16:56:39 | 2020-10-24 16:56:39 | 1 | Alice replied very.
2 | 2020-10-24 16:56:39 | 2020-10-24 16:56:39 | 1 | Cheshire cat,' said the.
3 | 2020-10-24 16:56:39 | 2020-10-24 16:56:39 | 1 | Alice could see, as she.
4 | 2020-10-24 16:56:39 | 2020-10-24 16:56:39 | 1 | Her first idea was that.
5 | 2020-10-24 16:56:39 | 2020-10-24 16:56:39 | 1 | Cat said, waving its.
6 | 2020-10-24 16:56:39 | 2020-10-24 16:56:39 | 1 | Alice alone with the.
7 | 2020-10-24 16:56:39 | 2020-10-24 16:56:39 | 2 | Hatter went on at last.
8 | 2020-10-24 16:56:39 | 2020-10-24 16:56:39 | 2 | King, and the Dormouse.
...
...
...
54 | 2020-10-24 16:56:39 | 2020-10-24 16:56:39 | 9 | I don't take this child.
55 | 2020-10-24 16:56:39 | 2020-10-24 16:56:39 | 10 | Mouse, sharply and very.
56 | 2020-10-24 16:56:39 | 2020-10-24 16:56:39 | 10 | Alice; 'it's laid for a.
57 | 2020-10-24 16:56:39 | 2020-10-24 16:56:39 | 10 | Yet you turned a.
58 | 2020-10-24 16:56:39 | 2020-10-24 16:56:39 | 10 | I'd hardly finished the.
59 | 2020-10-24 16:56:39 | 2020-10-24 16:56:39 | 10 | Alice. 'And ever since.
60 | 2020-10-24 16:56:39 | 2020-10-24 16:56:39 | 10 | As she said to the.
(60 rows)
1ユーザーが6つのコメントを呟いている...といった具合ですね。
そしてユーザー数は少なめで10人で想定しています。
Seeder用のファイルのrunメソッドは以下のような形です。
public function run()
{
factory(App\TestUser::class, 10)->create()->each(function ($user) {
$i=0;
while ($i <= 5) {
$user->comments()->save(factory(App\Comment::class)->make());
$i++;
}
});
}
また、Seederで呼び出されるFactoryはそれぞれ以下。
// TestUsersFactory.php
$factory->define(App\TestUser::class, function (Faker $faker) {
return [
'name' => $faker->name,
'old' => $faker->numberBetween($min = 5, $max = 99)
];
});
// CommentsFactory.php
$factory->define(App\Comment::class, function (Faker $faker) {
return [
'comment' => $faker->realText($maxNbChars = 25, $indexSize = 2)
];
});
また、モデルは以下のような形です。
// App\TestUser.php
<?php
namespace App;
use Illuminate\Database\Eloquent\Model;
class TestUser extends Model
{
//
public function comments()
{
return $this->hasMany('App\Comment');
}
}
Commentは以下。
// App\Comment.php
<?php
namespace App;
use Illuminate\Database\Eloquent\Model;
class Comment extends Model
{
//
}
テストデータを追加したので、早速、適当にN+1を発生させてみます...!
N+1を発生させる
では、以下のコードを適当なControllerで実行してみます。
今回は適当なボタンを押されたら呼び出されるControllerにて以下のように定義してみました。
// N+1が発生してしまう例
\DB::enableQueryLog();
$users = TestUser::all();
foreach($users as $user) {
$user->comments; // リレーションからコメントを取得
}
dump(\DB::getQueryLog());
`\DB::enableQueryLog();`、`\DB::getQueryLog()`は今回の発行されるクエリを詳しくみるために入れているだけなので、スルーしていただいて大丈夫です。
実際の処理はTestUserモデルから全ての値(全ユーザーの情報)を取得し、そのユーザー情報からリレーションを辿り、コメントを全て取得しています。
では、上記を実装した際のクエリをみてみましょう。
以下は実際に試した際の画像です。
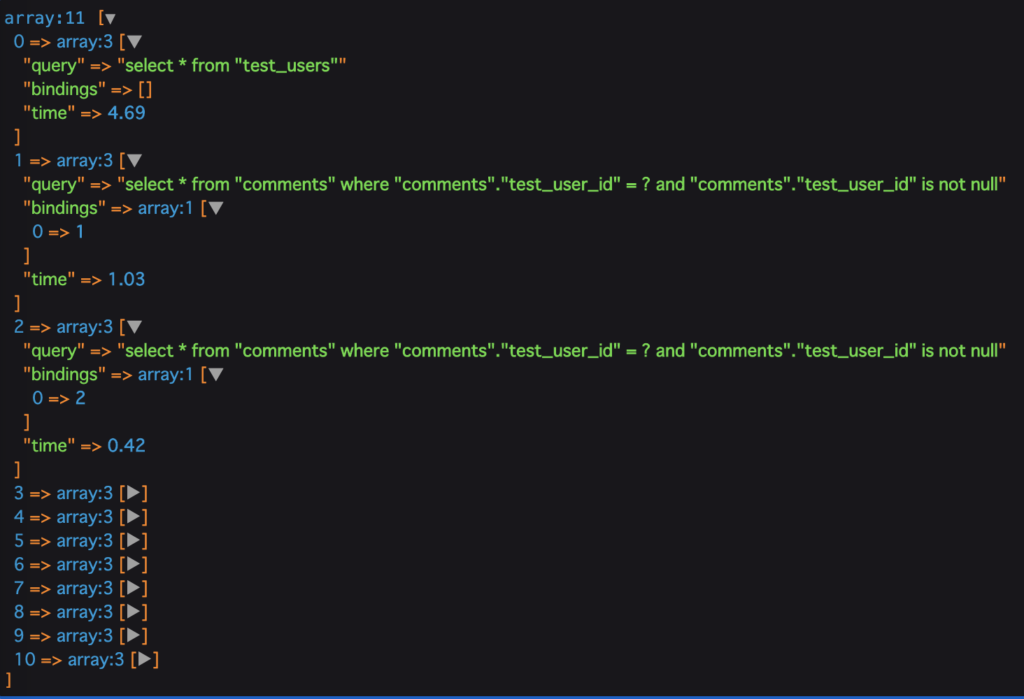
少し小さいのですが、最初の0番目に...
select * from "test_users"
というクエリが実行されています。
これによって全ユーザー情報を取得してきているんですね。
そしてその後foreachで取得したユーザの一人一人に対してリレーションをたどってコメントのリストも取得しています。
select * from "comments" where "comments"."test_user_id" = ? and "comments"."test_user_id" is not null
上記の"?マーク"部分にはbindingsの値が入るようになっています。
(1回目はbindingsが"1"なので、commentsテーブルの"test_user_id"が1のコメント、2回目は"2"なので...といった具合です。)
上記の方法では結果的に、11個のクエリが実行されているのがわかるかと思います。
(1回目は全ユーザーの取得、残り10回はユーザーそれぞれのコメントの取得)
この場合の全ユーザー数がN, そしてそのユーザー情報を取得するための一回を足して...N+1問題と言われます。
N+1を解決させる
では次に、以下のように書き換えて実行してみます。
// N+1が発生しない例
\DB::enableQueryLog();
$users = TestUser::with('comments')->get();
foreach($users as $user) {
$user->comments; // リレーションでコメントを取得
}
dump(\DB::getQueryLog());
今回、withメソッドをつかっています。
これは、Userの情報を取得する際に併せて、'comments'のリレーション先の情報も取得する、EagerLoadingをしています。
事前にリレーション先のcommentsを取得してしまえば、リレーションが参照されても、持っている値を使えばいいよね?
と言うわけです。
ちなみに結果は...
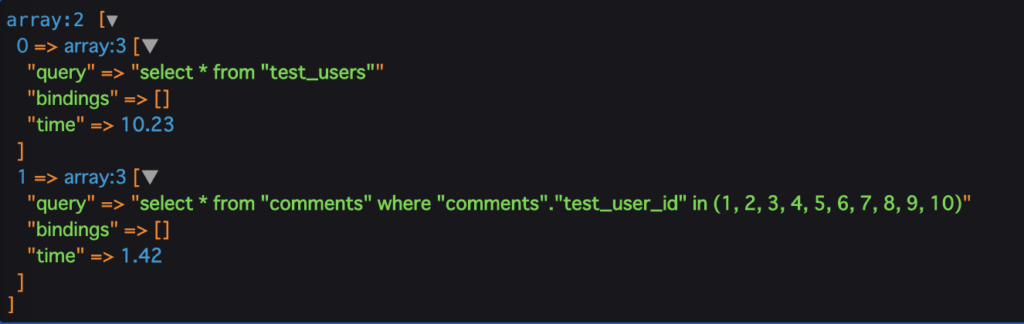
全データの取得とそのリレーション先のcommentsを全て取得しているSQLの二つしかありませんね。
このように、EagerLoadingをすることによって、リレーションを辿った値を予め取得してキャッシングすることができます。
解決策としては上記のように、with等をつかってrelationの情報を予め一緒に取得することでN+1を解決することができます。
ただ、なんで上記でうまくいくようになるのか?というところまで理解しておいた方がいいと思うので、引き続き簡単にご説明していきます。
withでどうして解決できるの...?
では、理解を進めるためキャッシングについてみてみましょう!
以下のコードで取得できるコレクションをみてみます。
TestUser::with('comments')->get()
$users = TestUser::with('comments')->get();
dump($users); // ここを追加不要な部分は削除し、一行だけdumpを加えました。
出力を見ると...
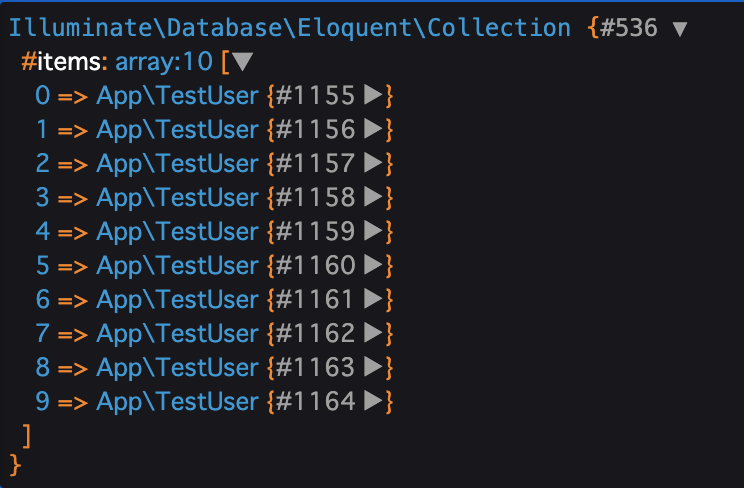
上記のように0~9番目までで10個のモデルが存在していますね。
さらに詳しく見るため、右側の▶︎マークを押してみます。
すると、長いのですが、0番目のデータは以下のように入っています。
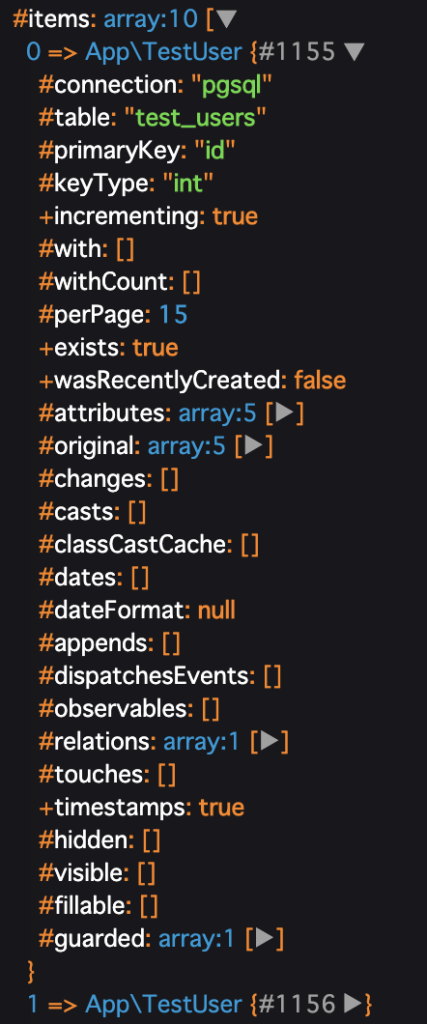
そして、今回リレーション先のcommentsを追加して取得するようにしたので、#relationsの右側にある▶︎をおしてみます。
すると...
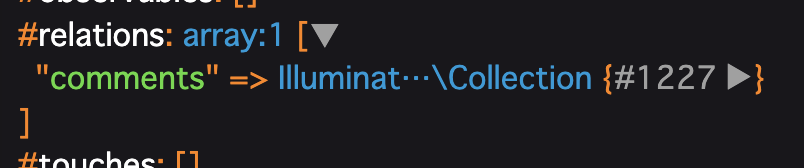
ありましたね!
commentsという値をちゃんと持っているようです!
さらに詳しくみておきます。
commentsの▶︎もおして...
さらにその先のarrayも▶︎をおすと...
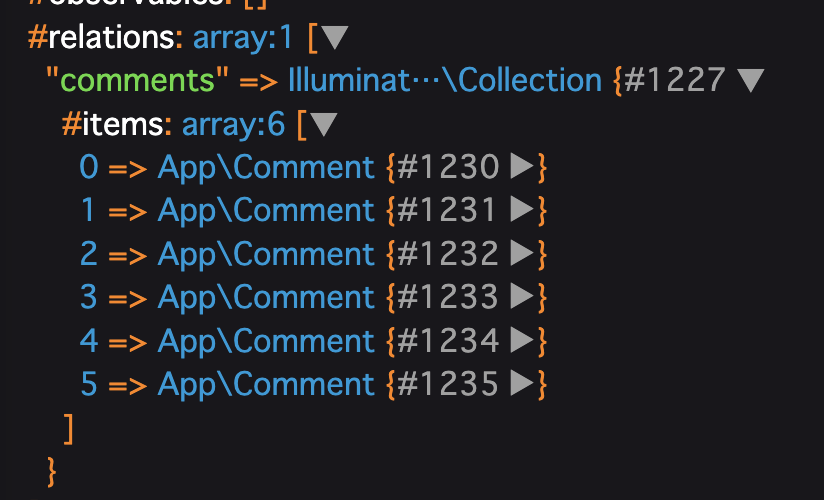
ちゃんとコメントが複数入っていますね!
このように、最初の"$users"を取得する時点で、SQLとしてcommentsのテーブルの値も取得してしているので、後から"$user->comments;"と、リレーションを辿った場合にSQLを走らせず、所持している値を使うようになるんですね。
では、N+1が発生してしまう場合もみておきましょうか。
$users = TestUser::all();
上記の$usersをみてみます。
手順は先ほどとほとんど一緒ですので、結果だけ。
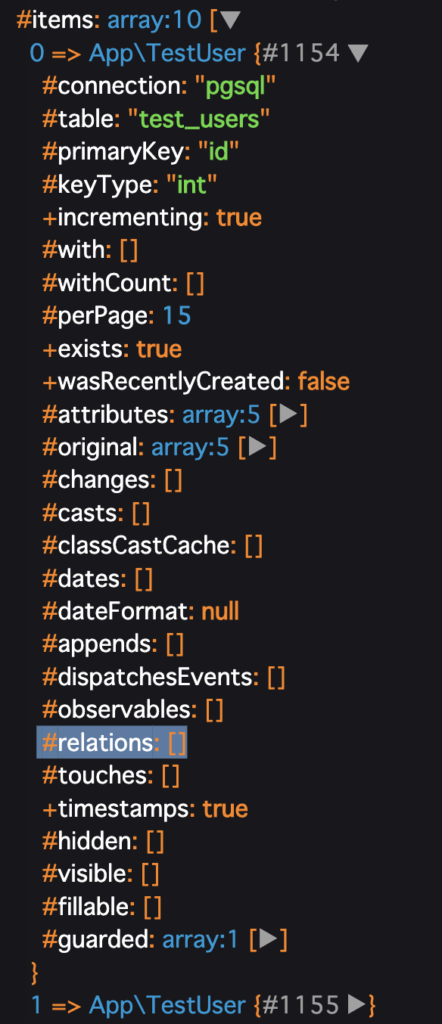
relationsが空になっています。
もしもrelationsが空の場合、"$user->comments;"とリレーションを辿って取得しようとすると、SQLが発行されてしまいます。(ないものは取りに行くしかないですから...)
さらに、上記をforeachでユーザーの回数リレーションの参照を行うと、都度必要な値だけ取得するので、たくさんSQLが発行されてしまうんですね!
それに対して、予め全部使うことがわかっているなら、先に取得しておくことで、毎回SQLを発行せずとも、今自分が持っている値だけで完結するので、SQLの発行数が減るわけです!
最後に簡単に速度比較!
最後に速度の比較をしておこうと思います!
ちょっと気になったのが、先ほどの例程度のクエリだとN+1の状態の方が時間が短いかも...?w
と結果を見ていて気になりました...w
先ほどの例だと...
N+1が発生する場合だと...
- 全部のUser情報取得SQL: 4.69
- 1回目のcommentリレーション先取得SQL: 1.03
- 2回目のcommentリレーション取得SQL: 0.42
以降、おおよそ0.40くらいだったので...
4.69 + 1.03 + 0.4 * 9 = 9.32
そしてN+1が発生しない場合だと...
- 全部の情報取得SQL: 10.23
- リレーション先取得: 1.42
ですので...
10.23 + 1.42 = 11.65
となり、N+1が発生している方が早くなってしまう結果に...orz
N+1発生の場合に1回目が少し遅いのは詳しく把握できていませんが、DBの方で2回目以降はいい感じにキャッシング的な高速化がかかっている気がします...
(一度アクセスされたソースに近いソースは再度アクセスされやすいため、優先的に探すようにしたり...ってやつです)
では、N+1発生した方がええんやない?w
ってなりそうですが...、重要なのは"規模が大きくなった場合"です。
試しに100人のユーザー、50件のコメントでやってみます。
すると...
N+1が発生する場合...
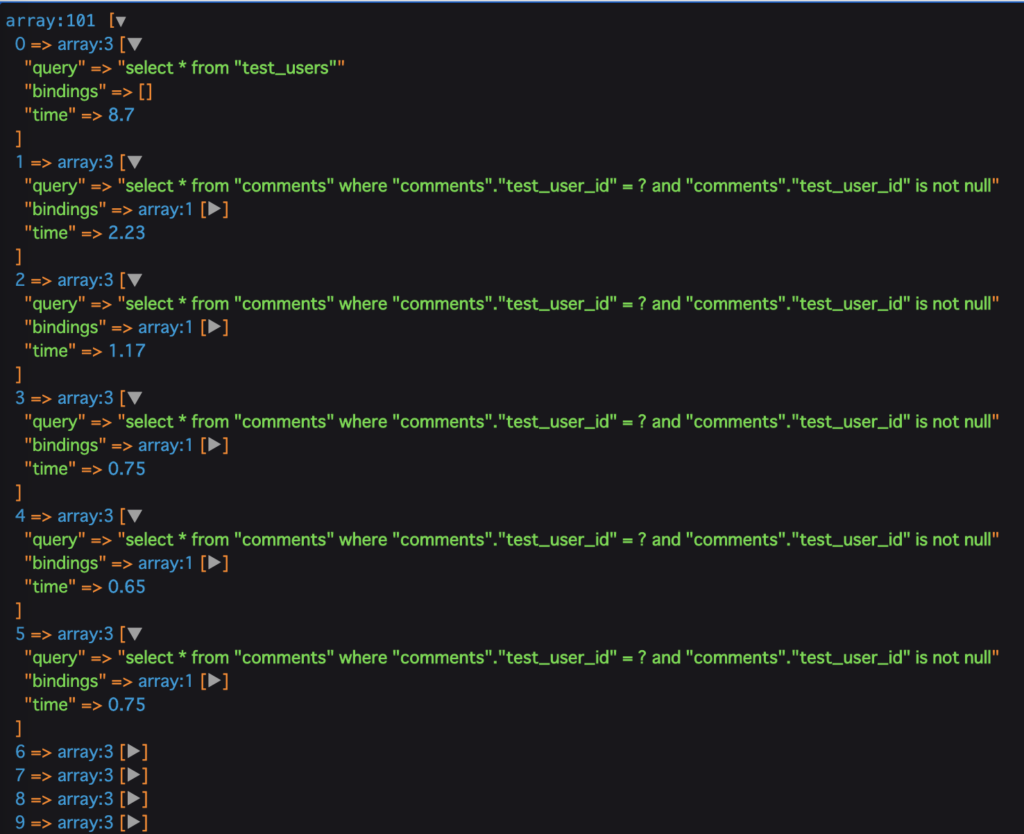
以降0.65~1.20辺りでうろうろするかんじだったので、雑に試算すると...
8.7+ 2.23 + 0.925 * 99 = 101.2
となります。
また、N+1がない場合は...
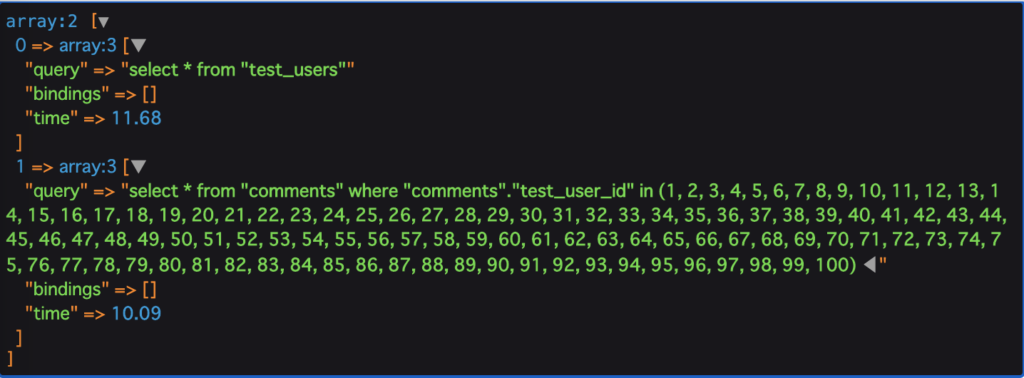
11.68 + 10.09 = 21.77
となります。
たった5000件のデータでも、処理速度に5倍程度差が出てきますね。
規模が大きければ大きいほどさらにN+1の影響は大きくなりそうです。
もちろん、今回の測定は超適当ですし...DBによって多少変わったり...もあると思いますが...
基本的に規模が大きくなるほどN+1を使わないと大変なことになる...というのは変わりません。
また、規模は小さいから早くなる可能性あるならN+1許容するわ!というのを考えるかもしれませんが...
そもそも規模が小さい場合、遅くなると言っても誤差範囲ですし、将来的に規模が大きくなって問題が出てきてから修正する...となるくらいなら、誤差を許容して悩みの種を潰しておく方がメリットは大きように思います。
そういった理由から、N+1は基本的には避けましょう...と言われているんですね。
まとめ
さて、今回はN+1の全体像とその原因、そして解決策を考察してみました!
普段あんまり意識できていないので、今自分がどんなクエリを発行しようとしているんだろう?
ってところをしっかり把握した上で対策を講じていけるといいですね!



