



どーも!
たかぽんです!
先日サミットに行ってからと言うもの、AWS周りのお勉強を本格的にせねば...ということで、色々触っていこうと思います...!
まず第一弾はAthenaです...!
目次
AWS Athenaって?
Athenaとは、S3のリソースなどから、クエリ(よくあるselect * from~みたいなやつですね)の形で情報の抽出ができるサービスになっています。
詳しくは下記を見ていただければ...と思いますが、ざっくり言うと、ビジネス的な要件で使っているcsvやログとして書き出す内容などを日付やcsvのカラムでいい感じにクエリ叩けるようになるやつ...!
みたいな感じです...!
なんとなく頭で理解してもやっぱり触ることに勝ることはないので、実際にS3にcsvファイルをputし、そのファイルをクエリで検索...と言ったことをやってみようと思います...!
やってみる...!
さて、それでは実践していきます...!
手順としては以下の内容をやっていきます...!
- S3にバケットを作成し、csvファイルを配置する(入力用データの参照用)
- S3にバケットを作成する(出力の書き出し用)
- Athenaのテーブルを作成
- selectでクエリを試す
- クエリの結果が出力用S3バケットに入っているかを確認する
ひとつづつやっていきますね...!
雑ですが...
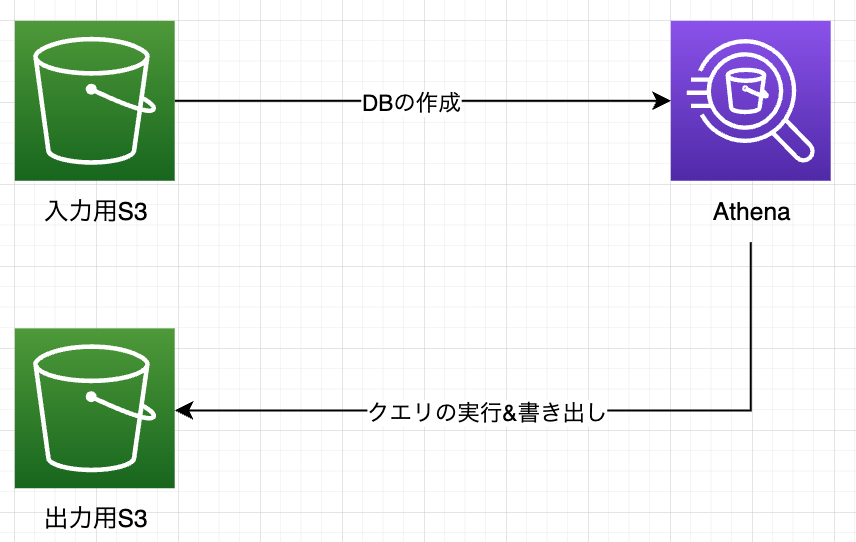
イメージこんな感じ...!
事前に一度だけAthenaのDBの作成をしておくことで、いつでもクエリさえ叩けばその結果を確認&書き出しすることができるようになります。
(AthenaのDBも切り分けようと思ったんですが、良さげな図なかったので、Athenaで合わせて表しています...!)
S3にバケットを作成し、csvファイルを配置する
では、まずはS3にバケットを作成して、csvファイルをPUTします。
ざっくりとこんな感じです...!
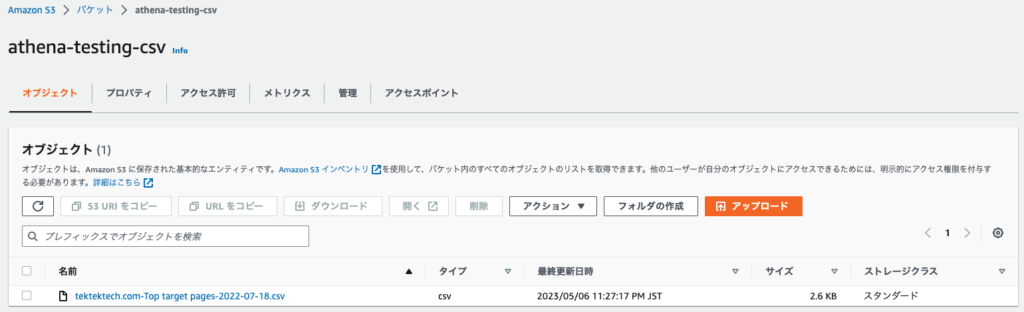
今回S3バケットとして、athena-testing-csvというバケットを作成し、csvファイルをPUTしました。
バケットの作成は基本デフォルトままで、バケット名だけ"athena-testing-csv"としてみました。
また、アップロードしたCSVの中身はなんでもいいので、今回は本ブログの被リンク一覧のCSVを持ってきました...w
こんな感じです。

三つのカラムがあるだけのcsvファイルになっていますね。
次は出力バケットを用意します...!
S3に出力用バケットを作成する
さて、今度はAthenaの出力を書き出すS3を作成します。
こちらもデフォルトまま、名前だけ"athena-testing-result"としておきました。
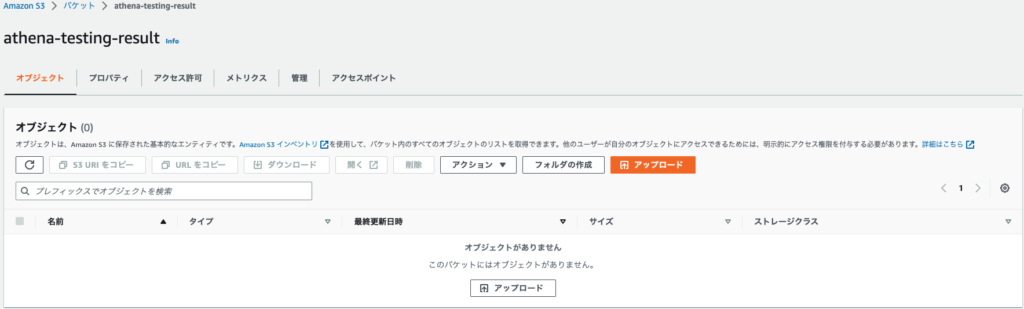
ここにAthenaで叩いたクエリの結果を保存していく感じですね...!
また、Athenaにて、この出力バケットに書き出されるように設定しておきます。
Athenaのクエリエディタから、"設定"の項目を開きます。

設定から右上にある"管理"のボタンを押すと詳細の管理画面がでてきます。
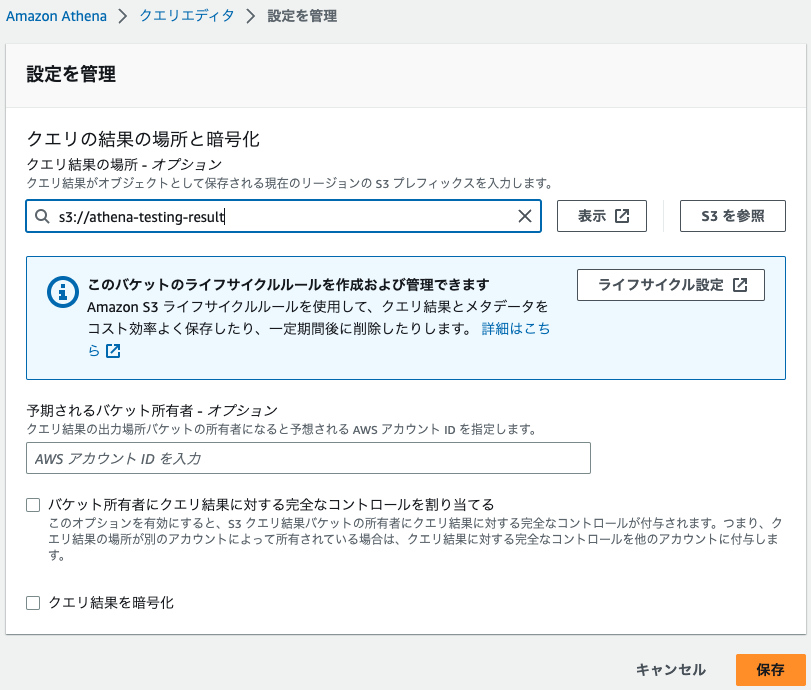
ここで先ほどの出力用S3バケットを指定してあげればOKです。
(ここから余談になりますが...どうもログを書き出さない設定はできなさそう・・・?そのため、不要な場合は出力用のS3でライフサイクルを短めに設定して書き出したログをすぐに消されるようにする...等で対応が必要になりそうです。)
Athenaのテーブルを作成
次はAthenaのテーブルを作成していきます...!
項目がいくつかあるので、デフォから変えた箇所だけ...!
まずは最初にAthenaからクエリエディタを開き、画面左側にある"作成"ボタンから、"S3バケットデータ"を選択します。
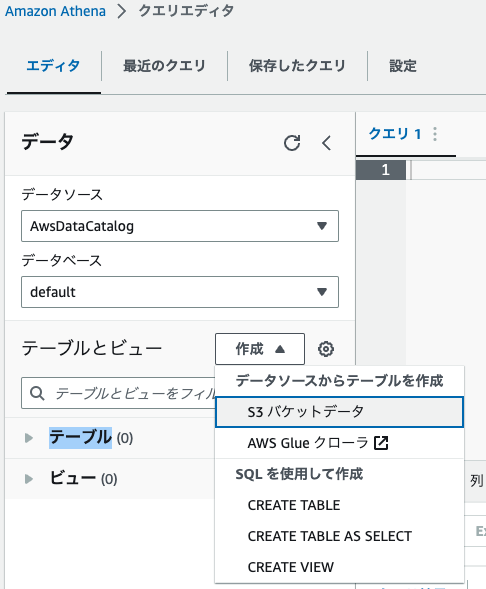
選択するとテーブル作成画面が出てくるかと思います。
上から順に見ていきます。
テーブルの詳細は任意の名称・説明を入れておきます。
データベース設定はdefaultでも良いかもですが、今回は新しく作成しておきます。
設定内容は下記画像を参考にしてください。
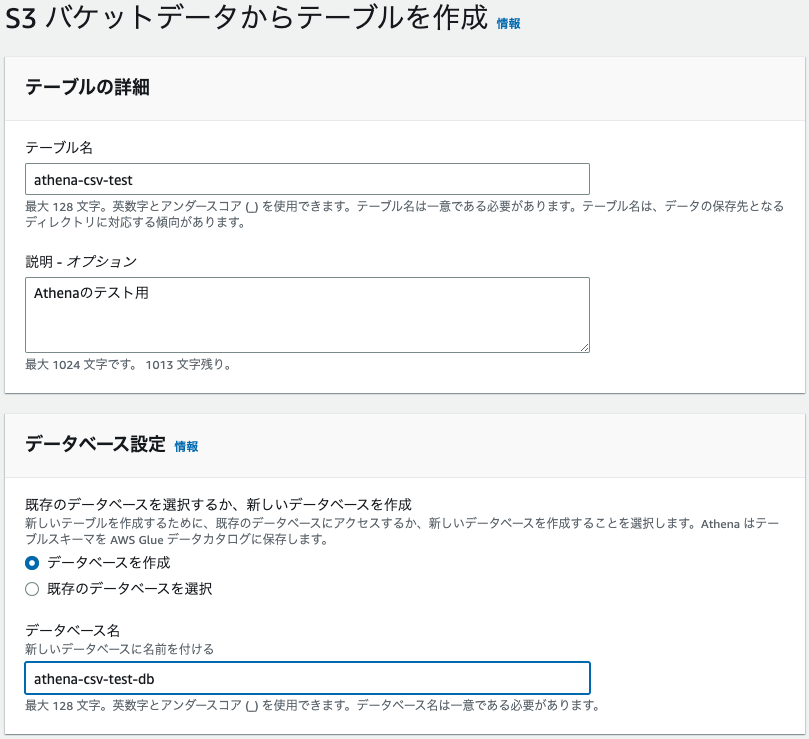
次はデータの設定周りです。
データセットは入力するcsvが配置されている場所を指定します。
データ形式はファイル形式がCSVなので、そこだけ変更します。
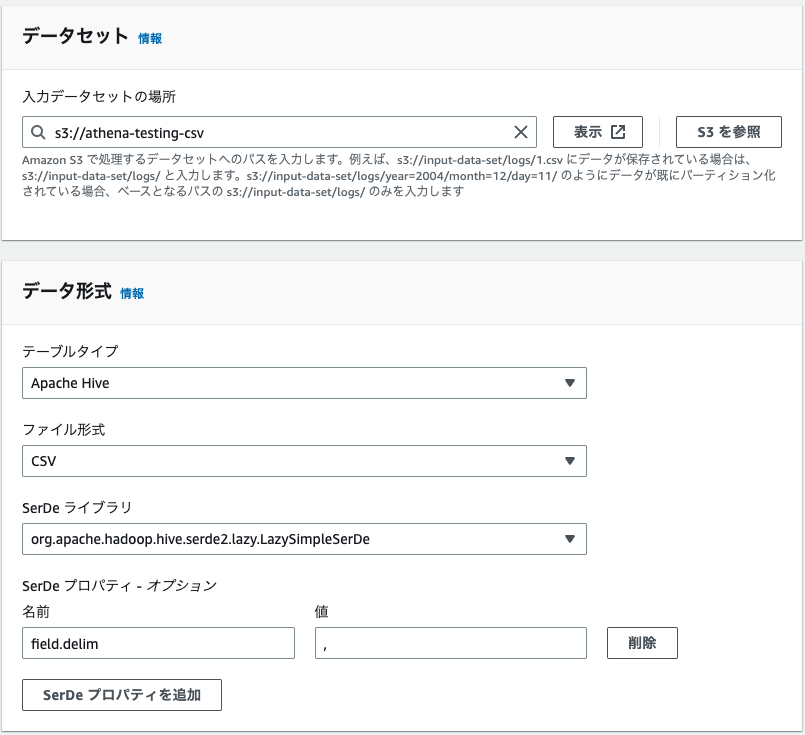
そして、最後にカラムの設定ですね。
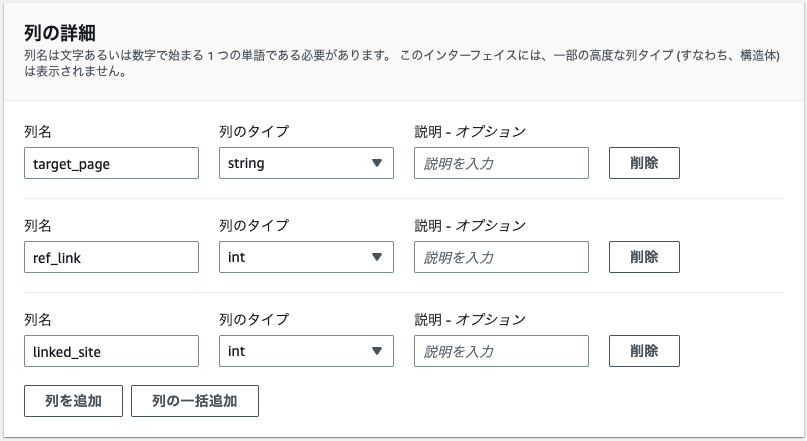
ここの設定に関しては実際のcsvの列のカラムをAthena上のクエリで指定する際の名称等になってきます。
select * from hoge where target_page = ... and ref_link = ...
みたいな感じですね。
紐付けがどうなっているのか気にはなりましたが、おそらくCSVの左から順にここの設定の上から適応されているようです。
残りはデフォルトままで大丈夫なので、テーブル作成をしていきます!

最後にちゃんとそれっぽいクエリが生成されていることを確認したら"テーブルを作成"を。
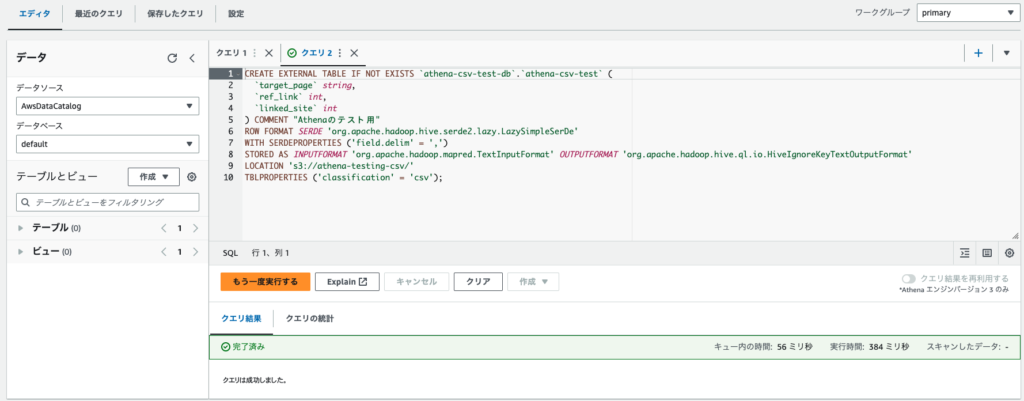
すると、上記のように画面がクエリエディタに戻り、"完了済み"となっていればテーブル作成が無事完了したはずです。
次にテーブルからselectしてみます...!
selectでクエリを試す...!
次に実際にクエリを試してみます...!
まず、"データベース"を先ほど作ったdbにすると先ほど作成したテーブルが出てきます。
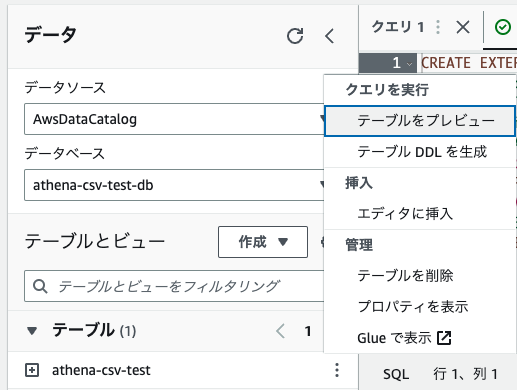
そのテーブルの右側の3つの点のアイコンから、"テーブルをプレビュー"を選択すると...?
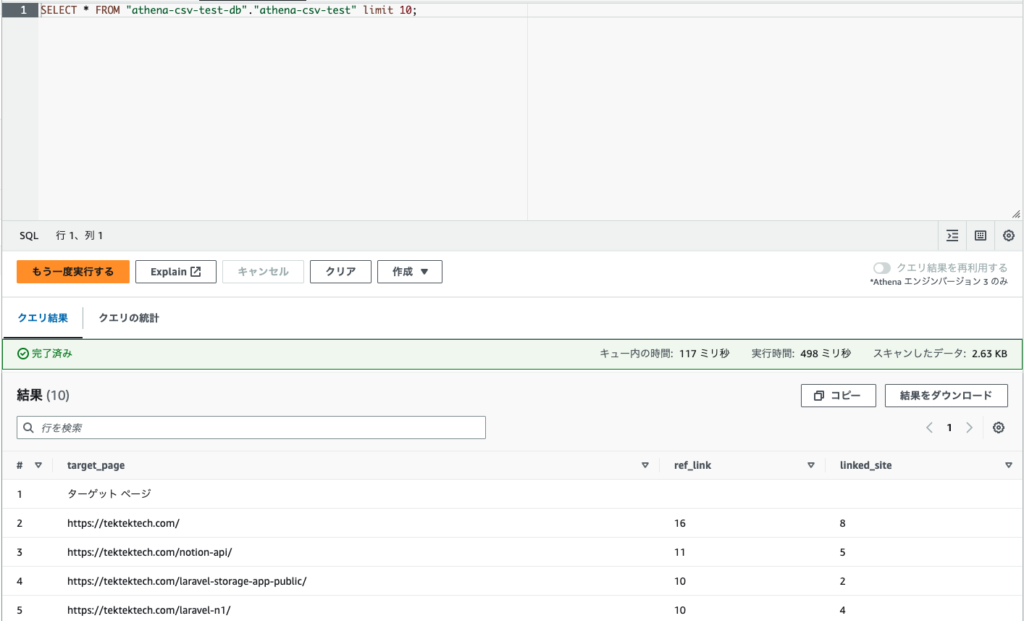
上記のような形で基本的なselect文が発行されます。
もちろん、SQLをご存知の方がいれば任意に書き換えてもらっても大丈夫です。
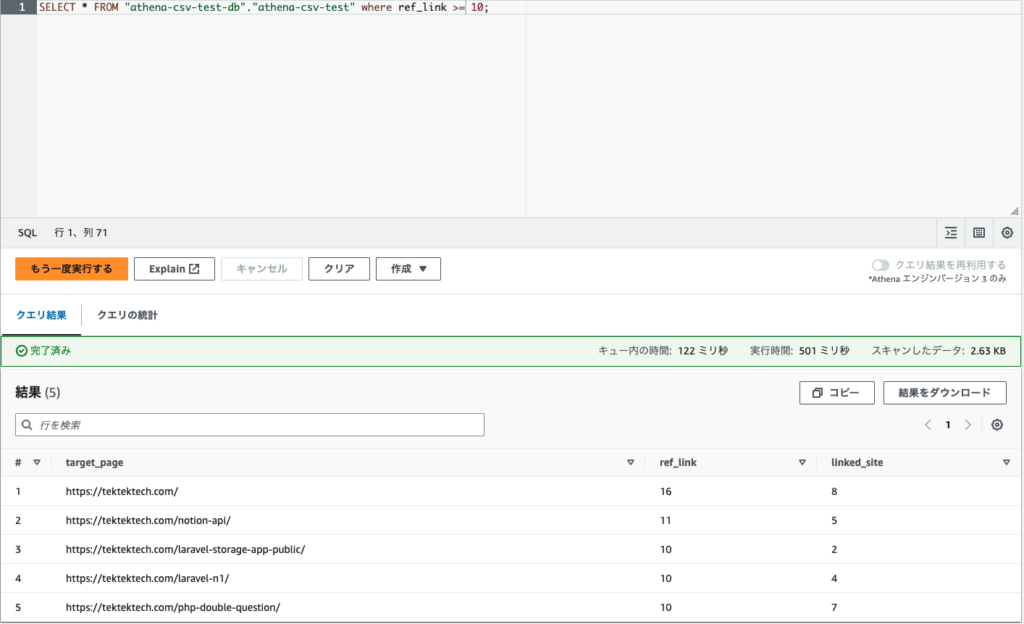
件数がちゃんと少なくなっているのがわかりますね。
では最後に出力用S3だけ確認しておきましょう。
クエリの結果を確認する
クエリの結果については以下で詳細を確認できるかと思います。
軽くお伝えしておくと...
クエリの保存有無で以下のパスへ配置される感じですね。
QueryResultsLocationInS3/[QueryName|Unsaved/yyyy/mm/dd/]
そのため...
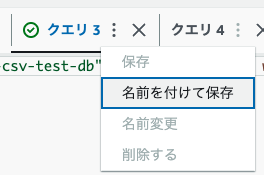
クエリに名前を付与して...?
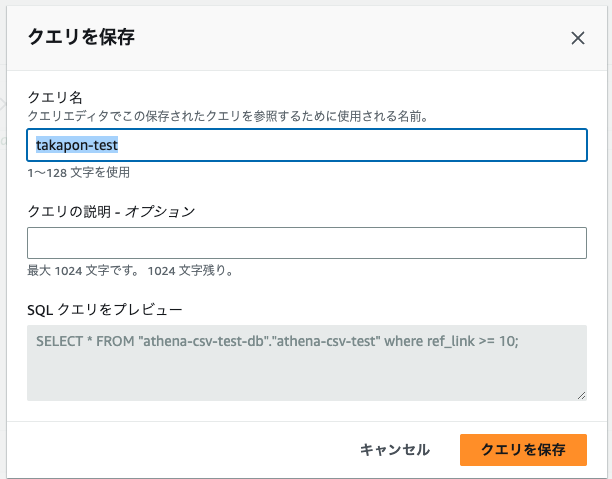
再度実行をすると...?
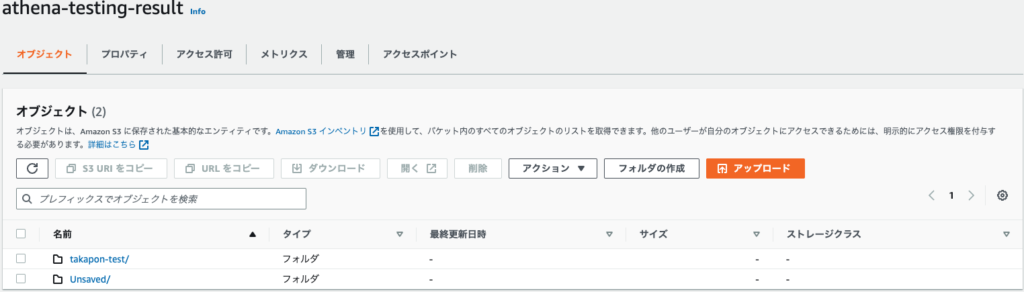
こんな感じになります。
具体的なデータは...
csvファイルとmetadataのファイルがありました。

csvファイルの方が出力内容になっていて、metadataも一応クエリ内容ではあるっぽいですが、バイナリ形式なので、人がみるためのものではないようです。
書き出されるファイルの詳細については下記を参照してください...!
実際のcsvファイルの中身はこんな感じでした。

不要なリソースの削除
もし本記事の内容をご自身の環境で試した場合は元の環境に戻す参考にしてください!
S3, Athenaのテーブルとデータベースを削除します。
S3は中身を空にしてから削除します。

今回作成した上記の右上にある"空にする"から削除した後、隣の"削除"から削除します。
Athenaに関しては下記でデータベースを削除します。
(筆者は先にテーブルも削除したのですが、おそらくDB削除だけでテーブルも消える気がします)
DROP DATABASE `athena-csv-test-db`;
もしテーブルがあることでエラーが出てしまった場合は合わせてdrop tableも試してみてください。
最後にAthenaの出力先のS3を削除したので、指定も消しておけば元通りになるかと思います。
また、もしクエリを保存した人はその"保存されたクエリ"の削除もしておくと良いかと思います。
まとめ
さて、今回はAthenaを簡単に使ってみました...!
今回は本当に最低限しか触っていないのですが、AthenaでクロールすることでS3のcsv更新を検知して都度最新状態でクエリを叩けるようにしたりもできるっぽいですし、他サービスと連携することで、他サービスのログをクエリで検索...といったこともできるようです。
筆者はSAAを狙っていて、ここまでにしておこうと思いますが、SAA取得後はもっと深堀して色々検証してみようと思います...!



