


どーも!
たかぽんです!
実は最近あまりブログかけていなかったのですが、ガッツリAWSの学習と自分用のポートフォリオサイトの作成に時間を割いていました...!
今年はもうちょっとアウトプットにも注力する予定なので、今年もよろしくお願いいたします!
と、言うわけで!年始はAWS周りの学習に合わせてその辺りのアウトプットを中心でやっていこうと思います!
第一弾...ということで、今回はAWSのプレイスメントグループについて調べてみようと思います!
目次
プレイスメントグループとは...?
プレイスメントグループとは、AWSのEC2というサービスにおいて選択できるオプションの一つです。
これは、文字通り、EC2のインスタンスを配置するルールのようなもので、相互に依存するEC2インスタンスを一定の決まりで一つのグループとして管理する...といったニュアンスに近いです。
2024年1月時点では...
- クラスター
- パーティション
- スプレッド
といった三種類のプレイスメントグループを作成することができます。
次節にてより詳細にお伝えしていきます!
クラスタープレイスメントグループ
クラスターは公式では以下の通り解説されています。
アベイラビリティーゾーン内でインスタンスをまとめます。この戦略により、ワークロードは、ハイパフォーマンスコンピューティング (HPC) アプリケーションで典型的な緊密に組み合わされたノード間通信に必要な低レイテンシーネットワークパフォーマンスを実現できます。
プレイスメントグループ
文字通りに受け取ると、AZ内でインスタンスをまとめて管理するため、インスタンス間での物理的な距離が比較的近くなります。
それによって、複数インスタンス同士の通信が発生し、尚且つ低レイテンシーな通信が要求されるアプリケーションを扱いたい場合はこのプレイスメントグループを選んだ方がよさそうです。
また、図形に直すと以下のようなイメージです。
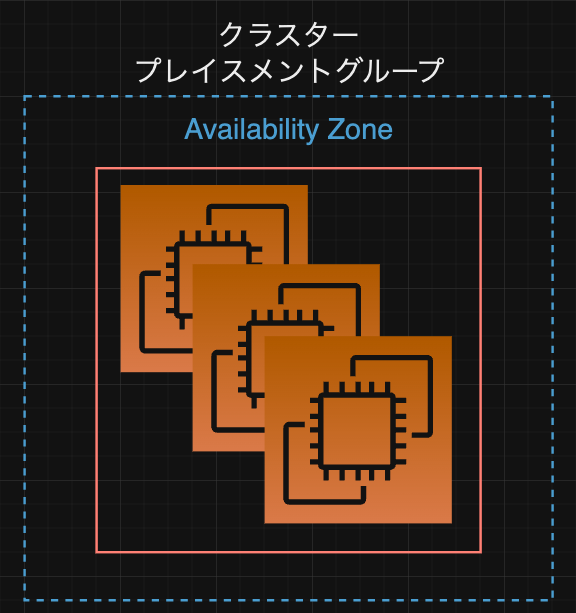
上記図形において、赤枠部分はひとつのハードウェア...と思ってもらうと良いかと思います。
クラスターの場合はその一つのハードウェア上で全てのEC2を起動する形になります。
また、クラスターの構成をする場合は以下が推奨されているようです。
- プレイスメントグループ内で必要な数のインスタンスを起動するには、1 つの起動リクエストを使用します。
- プレイスメントグループ内のすべてのインスタンスに同じインスタンスタイプを使用します。
ちょっとここからは筆者の推測になりますが...
1 つの起動リクエストに関しては、AWS側で全てのインスタンス実行に必要な容量を推定して、ハードウェアを選択する以上、分けて起動リクエストを送られると、先に起動が成功しても、後のリクエストにて容量エラーが発生して、結局停止して再度リクエストしてもらう感じになるので、であれば最初っから全部入れておいた方がいいよ...ってことな気がします。
また、同じインスタンスタイプを使用...に関しては、後述されているのですが...
クラスタープレイスメントグループの 2 つのインスタンス間のトラフィックの最大ネットワークスループット速度は、2 つのインスタンスのうち遅い方に制限されます。高スループットの要件があるアプリケーションの場合、要件に適合するネットワーク接続を備えたインスタンスタイプを選択します。
とあります。
つまり、インスタンスタイプが異なっていた場合、スループットが遅い方に制限がされます。
ただ、そもそもクラスターで構成する利点として高スループット...が要件としてあるはずで、であればどちらも低いインスタンスタイプに揃えるか、高いインスタンスタイプに揃えるか....の方が効率が良いはずです。
そのため、スループット的に無駄のない同じインスタンスタイプで揃えることを推奨しているのかな?と思いました。
(もちろん、スループット以外の要件で仕方なく一方は高い性能のインスタンスタイプである必要があり、一方はコストを抑えるため低い性能のインスタンスタイプにしている...のであれば仕方ない面はあると思います)
パーティションプレイスメントグループ
次はパーティションプレイスメントグループです。
ここでは"パーティション"という単位がでてきます。
これは、あるパーティションにはいくつかのハードウェアが載ったラックがあり、ラックには独自のネットワークおよび電源があります。
つまり、いくつかのハードウェアが有線で繋がっていて、電源やネットワークを共有している集まり...といった単位になります。
このパーティションがいくつかあり、パーティションごとにEC2を振り分けて配置するのがパーティションプレイスメントグループです。
図にすると以下のようなイメージです。
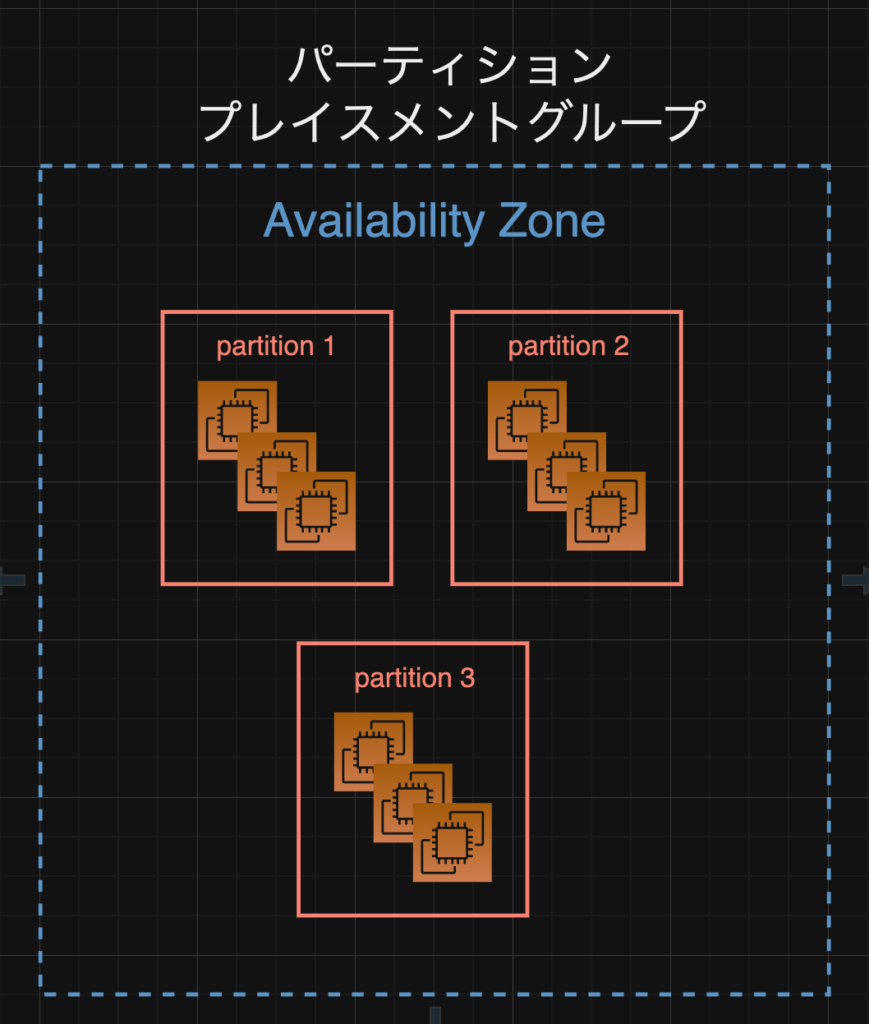
partitionの間では物理的なハードウェア、ネットワークや電源を共有していないため、ある程度分散が効いています。
詰まるところ、どこか一つのpartitionにて、電源トラブルがあると、そこのpartition内で動いているEC2は影響を受けるかもしれないですが、他のpartitionは問題なく動作するはずです。
逆に、先ほどのクラスターの場合は、上記いずれかのpartitionのある一つのハードウェアに集積しているため、もしそのハードウェアが所属するパーティションにて電源トラブルが発生したら全機能が影響をうけるかと思います。
使用用途として...
HDFS、HBase、Cassandra などの大規模な分散および複製ワークロードを異なるラック間でデプロイするために使用できるようなので、ある処理を複製して、複数パーティションで扱うことで、ワークロードが途切れないようにすることができるっぽいですね...!
また、デフォルトだとパーティションプレイスメントグループでEC2を起動すると、指定したパーティション数で均等に分散をするように配置されるようです。
ただし、インスタンスの配置場所をより細かく指定して制御することも可能です。
また、こちらもインスタンスの開始や起動する際、ハードウェアが不足している場合失敗するケースがあるようです。
ただ、説明を見た感じだと時間経過でちょっと待ってから再度試行するしかなさそう?な感じでした。
パーティションプレイスメントグループでインスタンスを開始または起動し、リクエストを実行するための固有のハードウェアが不足している場合、そのリクエストは失敗します。Amazon EC2 では、時間の経過とともに、より明確なハードウェアを利用できるようになるため、後でリクエストを再試行できます。
スプレッドプレイスメントグループ
最後に、スプレッドプレイスメントグループです!
こちらは究極の分散ですね...w
先ほどパーティションがあったと思うのですが、全てのEC2を別々のパーティションのあるハードウェアに配置する...といった形のようです。
つまり、partition1にて電源障害があったとしたら影響があるのは1つのEC2のみ....といった具合ですね。
図にすると以下のようなイメージです。
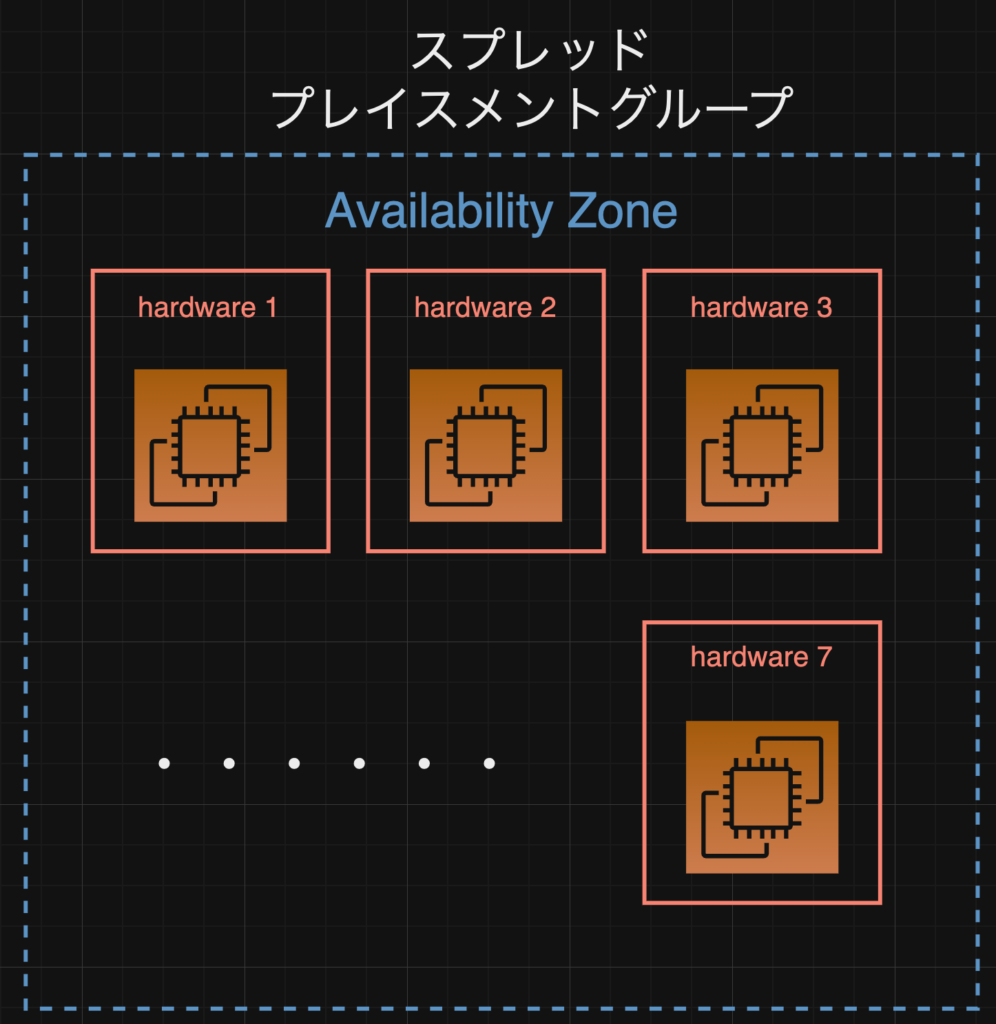
上記のように全てのEC2が別のハードウェアにて動いている形です。
なおかつ、全てが別のpartitionに所属するハードウェアなので、ネットワークや物理てきな電源など、共有していません。
先ほども記載した通り、AZにはpartitionは最大でも7つしかありません。そうすると、完全にネットワーク・電源を分離したハードウェアも最大で7つが上限になります。
そのため、スプレッドプレイスメントグループで運用できるのもAZあたり最大7つの実行中のインスタンスになります。
また、スプレッドプレイスメントグループには二種類あり、前述した内容は"ラックスプレッドプレイスメント"と呼ばれていて、AWS側のデータセンターを用いた構成になります。
もう一方のプレイスメントグループはホストレベルのスプレッドプレイスメントグループとよばれており、こちらはオンプレミスでの運用に用いるOutpostsの機能として提供されています。
つまり、オンプレミス環境で"ホスト"と呼ばれるOutpostの基盤となるハードウェアを用意し、その上で分散をするための構成となっています。
試してみた!
と、言うわけで...!
ちょっと設定もして試してみようと思います!
設定方法はざっくりと以下の手順になります。
・プレイスメントグループを作成する
・EC2インスタンスを作成する
・作成したEC2インスタンスのプレイスメントグループを確認
一つづついきますね!
プレイスメントグループの作成
口頭よりも動画!ということで、動画撮ってみました!
最後ec2も立てようとしてエラー出ちゃっていますが、一旦プレイスメントグループの作成までで...w
ちなみにエラー内容はt2.micro等のバーストできるインスタンスタイプではプレイスメントグループの設定ができなかったため...でした...w
簡単に説明しておきますと、
クラスターは単純にプレイスメントグループの名称と"クラスター"の指定のみです。
スプレッドはラックタイプか、先の説明に出てきたホストタイプ(Outpostのオンプレでの設定)が選べます。
パーティションは用いるパーティション数を指定することができます。
そのため、このような形でまずはプレイスメントグループで振り分けのグループを定義してあげます。
引き続き、EC2も立ててみます!
EC2(for cluster)の作成
ではcluster用のEC2を作成します。
先ほどエラーが出ていたように無料枠のインスタンスタイプではだめそうだったため、有料ですが、Armを指定して、m6系のインスタンスタイプを指定し、EC2は作るだけなので、キーは不要です。
また、クラスターグループなので、EC2は2つ起動しています。
その後、起動したEC2のプレイスメントグループがちゃんと同じtest-clusterになっていることが確認できました。
EC2(for partition)の作成
ほぼ一緒ですが、partitionも見ておきます。
先ほどパーティションの数は3つに指定していたため、試しに4つのインスタンスを起動してどうなるか見てみました。
4つのインスタンスが作成された後、partition1に2つ、他は1つづつのインスタンスが割り振られていることがかくにんできました。
基本的には均等に、溢れた分は1から順に...といった感じなのかな?と思います。
EC2(for spread)の作成
最後にspread用のEC2を作成していきます。
設定内容自体はほぼ一緒です。
spreadに関してもclusterと似ていて、全てのインスタンスがtest-spreadとなっていることが確認できました。
partitionごとにも分かれているとは思いますが、まぁ別々でどこのパーティションかわかったところで別のインスタンスと一緒になることはないので、わざわざ番号を出していないのかなと思います。
番外編(spreadのmaxを超えたインスタンス=8インスタンス)
さて、最後に、先ほどspread placementを見ていると、やっぱり最大=partition数だよな...?と。
それでいくと、spreadの設定で8インスタンスを起動しようとするとどうなるのか...?気になったので試してみようと思います。
8件のEC2を建てようとした際のエラーメッセージは以下の通りでした。
インスタンスを起動できませんでした
We currently do not have sufficient m6g.medium capacity in zones with support for 'gp3' volumes. Our system will be working on provisioning additional capacity.
ちなみに、時間をおいて試しても変わらなかったため、エラーメッセージはキャパシティ不足...となっていますが、やはりそもそもの上限が7件なのだろう...と思います。
もしかしたら、今後partitionの数が増えて追加できるようになるかも・・・?ですが、現場からは以上です!
まとめ
さて、今回はEC2の配置戦略であるプレイスメントグループについて色々と深掘りしてみました。
ちなみに、今回の内容はほぼ以下の公式ページから読み取った内容になっているため、詳細はこちらも合わせてご確認ください。
正直筆者は業務で触ることはほぼないと思う&個人開発でもそこまで意識(物理的な障害を考慮)することはないかなぁ...とは思いますが、そういったインフラの考え方に触れるだけでも価値あることかなぁと思っています。
それに、今後AWSの試験でプレイスメントグループ関連の問題が来た場合自信を持って回答できる気がします...!
これから学習をつづけつつ、AWS周りも記事にまとめていければとおもうので、他のサービス等もおまちいただければ...と...!
それでわ!


